| < Previous by Date | Date Index | Next by Date > |
| < Previous in Thread | Thread Index | Next in Thread > |
[reSIProcate] Shared Pointers (was Re: Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex)
- From: Adam Roach <adam@xxxxxxxxxxx>
- Date: Tue, 17 Apr 2007 09:41:46 -0500
Ryan Kereliuk wrote:
Way, way back when (during some of the pre-coding design talks), it was decided that SharedPtr objects wouldn't be part of resiprocate because they had caused so much trouble in the VOCAL stack. Perhaps Cullen can refresh my memory about what sorts of problems were encountered in VOCAL? (Forgive the HTML, but this really needs diagrams) I wasn't part of the VOCAL work, but I've worked with shared pointers and large developer pools often enough to know where the pitfalls are, and I can make a pretty good guess about where things went wrong in the original VOCAL stack. Shared pointer constructs in general must do one of two things: they must either have an intrusive count in the pointed-to object (which requires the object to know that it is smart-pointed-to), or it must have an intermediate object, disjoint from the pointed-to object, that contains this reference count. Boost takes the latter approach.  So far, so good. Now, when you pass these smart pointers around (i.e., copy them), the smart pointers themselves are "smart" enough to know to keep using the same intermediate reference counting object. 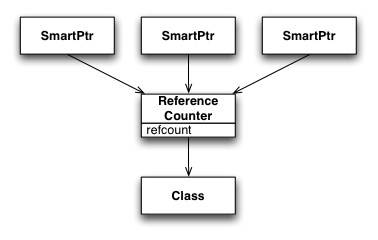 And, of course, the last smart pointer to get deleted cleans up the whole structure. This all works pretty elegantly, as long as everyone knows how to use smart pointers safely. However, that's not what usually happens. What usually happens is that someone gets to a point where they think they need a raw pointer to the class (either because of an existing API, or because they simply misunderstand the nature of the smart pointer behavior). And although it's possible to craft the API to smart pointers to make getting a raw pointer somewhat tricky to figure out, you'd be surprised how quickly a determined (albeit misguided) developer will be able to do so. Once this happens, you end up with a situation in which ownership can become muddied: 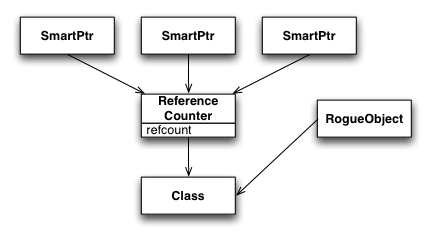 What invariably happens, though, is that this rogue object (or some class that uses it) will find an API that requires the use of a smart pointer. Well, that's no problem -- it's trivial to create a smart pointer from a raw pointer. What we have now looks something like this: 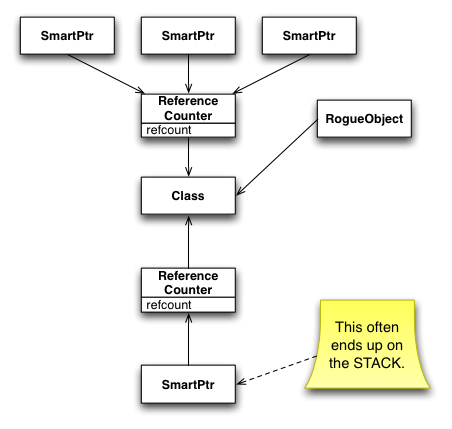 All the pieces are now in place for things to go horribly, horribly wrong. In fact, backing out of this situation once it is set up like this is pretty much impossible. Once the second set of smart pointers goes away (which often is as soon as the current method exits), the class is deallocated. 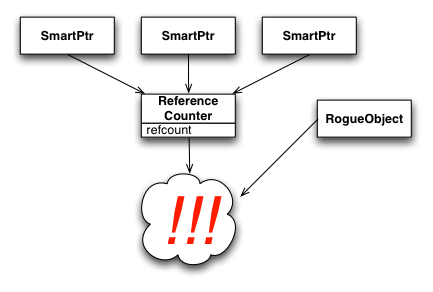 The lesson is: smart pointers have their uses in cases where you *REALLY* *REALLY* need to "share" ownership of an object between two logically distinct units of code. However, they aren't free, and the price is actually increased vigilance (most people assume smart pointers allow decreased vigilance, but it doesn't work out that way) and *EDUCATION* of the developer community about how to use smart pointers without blowing your foot off. In this case, the take-away should be: if you *can* get by with clear transfer of ownership (and I think we *can*), then it is far better to do so than to taunt fate by adding smart pointers. /a |
- Follow-Ups:
- References:
- Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash: inside resip/stack/Transaction::process method contains complex
- From: Jason Fischl
- Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- From: Scott Godin
- Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- From: Robert Sparks
- Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- From: Ryan Kereliuk
- Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash: inside resip/stack/Transaction::process method contains complex
- Prev by Date: Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- Next by Date: Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- Previous by thread: Re: [reSIProcate] Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex
- Next by thread: Re: [reSIProcate] Shared Pointers (was Re: Fwd: [reSIProcate-commit] resiprocate 7077 nash:inside resip/stack/Transaction::process method contains complex)
- Index(es):